NCCL
集体通信原语¶
原语介绍¶
Broadcast¶
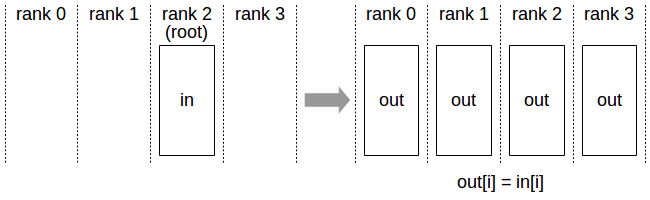 初始:只有GPU0上有数据
GPU0将DATA广播到GPU0, GPU1, GPU2, GPU3.
最终:每个GPU数据一样
初始:只有GPU0上有数据
GPU0将DATA广播到GPU0, GPU1, GPU2, GPU3.
最终:每个GPU数据一样
Scatter¶
初始:只有GPU0上有数据 GPU0将DATA分片再分发给GPU0, GPU1, GPU2, GPU3. 最终:每个GPU数据不一样
Gather¶
Scatter的反向操作 初始:每个GPU上有不同的数据 GPU0将GPU0, GPU1, GPU2, GPU3.的数据收回 最终:GPU0有完整的数据
All-Gather¶
 Gather + Broadcast
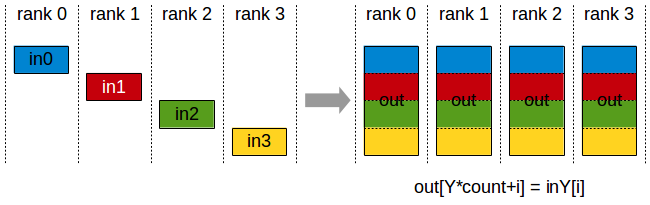
初始:每个GPU上有不同的数据
最终:每个GPU有完整的数据
Gather + Broadcast
初始:每个GPU上有不同的数据
最终:每个GPU有完整的数据
Reduce¶
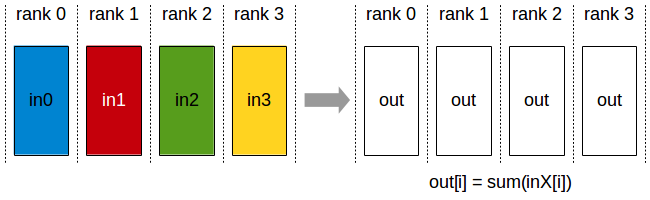
 初始:每个GPU上有不同的数据
将所有GPU的数据进行规约(求和,求积,矩阵运算等不改变维度)计算,将结果归于主节点GPU0(或其他GPU)
最终:GPU0(或其他单个GPU)有规约后的结果
初始:每个GPU上有不同的数据
将所有GPU的数据进行规约(求和,求积,矩阵运算等不改变维度)计算,将结果归于主节点GPU0(或其他GPU)
最终:GPU0(或其他单个GPU)有规约后的结果
All-Reduce¶
 Reduce + Broadcast
或者ReduceScatter + AllGather
初始:每个GPU上有不同的数据
最终:每个GPU有规约后的结果
Reduce + Broadcast
或者ReduceScatter + AllGather
初始:每个GPU上有不同的数据
最终:每个GPU有规约后的结果
Reduce-Scatter¶
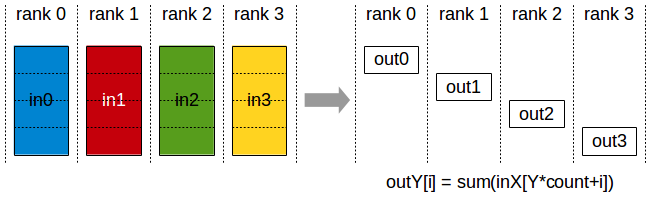 初始:每个GPU有不同的数据
中间步骤:每个GPU上的数据分维度进行规约操作,然后不同维度Scatter分发到不同GPU上
最终:每个GPU上有不同维度的规约之后的操作
初始:每个GPU有不同的数据
中间步骤:每个GPU上的数据分维度进行规约操作,然后不同维度Scatter分发到不同GPU上
最终:每个GPU上有不同维度的规约之后的操作
All-to-All¶
Gather-Scatter 初始:每个GPU上有不同的数据 中间步骤:每个GPU上的数据分维度进行Gather操作,然后将不同维度Gather在一起的数据Scatter分发到不同的GPU上 最终:每个GPU上有不同维度合并的数据(注意:不是规约中的SUM)
原语实现细节¶
NCCL通常使用一个或多个环形拓扑,来实现上述通信原语,能够得到最大化的带宽利用率。在nccl-test工具中,默认拓扑就是Ring。
Broadcast¶
数据传输流程:GPU0→GPU1→GPU2→GPU3 优化:分块传输可提高最终速度
All-Reduce¶
初始:每个GPU都有不同的数据(维度相同,数据不同) 步骤一:多个step进行,每个step都有两个GPU之间进行一个维度的Reduce操作 中间结果:步骤一多个step之后,每个GPU都有一个维度的数据是Reduce之后。 步骤二:每个GPU将Reduce之后的维度的数据Broadcast到其他GPU上 最终:每个GPU都有不同维度Reduce之后的结果(完全相同)
All-Gather¶
初始:每个GPU都有不同的数据 中间步骤:多个step,每个step都有GPU中间数据的tranfer 最终,每个GPU都有完整的数据
并行方式¶
数据并行(DP)¶
训练场景¶
每个 GPU 都运行相同的模型代码,而数据集被拆分为多份分配给不同的 GPU 进行训练。每轮迭代完成后,需要通过 AllReduce 操作进行同步。 AllReduce = ReduceScatter + AllGather 或者AllReduce = Reduce + Broadcast 初始:模型参数分散在各个GPU上 步骤一:All-Gather操作让每个GPU上有完整的模型参数 步骤二:每个GPU(模型)上针对不同数据进行Forward Pass 步骤三:每个GPU(模型)针对本地Backward Pass进行更新 步骤四:针对所有GPU做All-Reduce操作,进行梯度累计更
张量并行(TP)¶
利用多头注意力机制进行张量并行操作,每个头计算独立分配到不同的GPU上,通过All-Reduce操作同步矩阵乘法结果。
流水线并行(PP)¶
将模型的多个层(stage)分在不同的GPU上,通过点对点通信
序列并行(SP)¶
专家并行()¶
参考文章¶
Collective Operations — NCCL 2.23.4 documentation 一文讲清 NCCL 集合通信原理与优化 - 极术社区 - 连接开发者与智能计算生态